
Introdução a programação#
O que é programar#
Programar é simplesmente o ato de inserir instruções para o computador executar. Essas instruções podem processar alguns números, modificar texto, procurar informações em arquivos ou comunicar-se com outros computadores pela Internet.
Todos os programas usam instruções básicas como blocos de construção. Aqui estão alguns dos mais comuns, em inglês:
“Do this; then do that.” “If this condition is true, perform this action; otherwise, do that action.” “Do this action exactly 27 times.” “Keep doing that until this condition is true.”
[Swe19]
Você também pode combinar esses blocos de construção para implementar decisões mais complexas. Por exemplo, aqui estão as instruções de programação, chamadas de código-fonte , para um programa simples escrito na linguagem de programação Python. Começando no topo, o software Python executa cada linha de código (algumas linhas são executadas apenas se uma determinada condição for verdadeira ou então o Python executa alguma outra linha) até chegar ao final.
passwordFile = open('SecretPasswordFile.txt') #atribui conteúdo do arquivo a variável passwordfile
secretPassword = passwordFile.read() #cria uma váriável secretPassword atribui o conteúdo de passwordfile
print('Enter your password.') #mostra na tela a frase Enter...
typedPassword = input() #cria outra vária typedPassword e requer entrada de conteúdo ao usuário
if typedPassword == secretPassword: #estrutura condicional para conferência da senha
print('Access granted')
if typedPassword == '12345':
print('That password is very easy.')
elif typedPassword == 'cpd066':
print('Computação Aplicada.')
else:
print('Access denied')
Enter your password.
Access denied
Na verdade, ser bom em programação não é muito diferente de ser bom em resolver quebra-cabeças
Encontrando Ajuda#
Por exemplo, vamos causar um erro propositalmente
Como Obter Ajuda no Python#
1. Usando a função help()#
help(print) # Exibe informações sobre a função print
help(str) # Exibe informações sobre a classe str
Help on built-in function print in module builtins:
print(*args, sep=' ', end='\n', file=None, flush=False)
Prints the values to a stream, or to sys.stdout by default.
sep
string inserted between values, default a space.
end
string appended after the last value, default a newline.
file
a file-like object (stream); defaults to the current sys.stdout.
flush
whether to forcibly flush the stream.
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return bool(key in self).
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| __str__(self, /)
| Return str(self).
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Call keyword.iskeyword(s) to test whether string s is a reserved identifier,
| such as "def" or "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| removeprefix(self, prefix, /)
| Return a str with the given prefix string removed if present.
|
| If the string starts with the prefix string, return string[len(prefix):].
| Otherwise, return a copy of the original string.
|
| removesuffix(self, suffix, /)
| Return a str with the given suffix string removed if present.
|
| If the string ends with the suffix string and that suffix is not empty,
| return string[:-len(suffix)]. Otherwise, return a copy of the original
| string.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the substrings in the string, using sep as the separator string.
|
| sep
| The separator used to split the string.
|
| When set to None (the default value), will split on any whitespace
| character (including \n \r \t \f and spaces) and will discard
| empty strings from the result.
| maxsplit
| Maximum number of splits.
| -1 (the default value) means no limit.
|
| Splitting starts at the end of the string and works to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the substrings in the string, using sep as the separator string.
|
| sep
| The separator used to split the string.
|
| When set to None (the default value), will split on any whitespace
| character (including \n \r \t \f and spaces) and will discard
| empty strings from the result.
| maxsplit
| Maximum number of splits.
| -1 (the default value) means no limit.
|
| Splitting starts at the front of the string and works to the end.
|
| Note, str.split() is mainly useful for data that has been intentionally
| delimited. With natural text that includes punctuation, consider using
| the regular expression module.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| translate(self, table, /)
| Replace each character in the string using the given translation table.
|
| table
| Translation table, which must be a mapping of Unicode ordinals to
| Unicode ordinals, strings, or None.
|
| The table must implement lookup/indexing via __getitem__, for instance a
| dictionary or list. If this operation raises LookupError, the character is
| left untouched. Characters mapped to None are deleted.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs)
| Create and return a new object. See help(type) for accurate signature.
|
| maketrans(...)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
2. Usando dir() para listar atributos e métodos#
print(dir(str)) # Lista todos os métodos da classe str
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
3. Documentação embutida com .__doc__#
print(str.__doc__) # Exibe a documentação da classe str
print(print.__doc__) # Exibe a documentação da função print
str(object='') -> str
str(bytes_or_buffer[, encoding[, errors]]) -> str
Create a new string object from the given object. If encoding or
errors is specified, then the object must expose a data buffer
that will be decoded using the given encoding and error handler.
Otherwise, returns the result of object.__str__() (if defined)
or repr(object).
encoding defaults to sys.getdefaultencoding().
errors defaults to 'strict'.
Prints the values to a stream, or to sys.stdout by default.
sep
string inserted between values, default a space.
end
string appended after the last value, default a newline.
file
a file-like object (stream); defaults to the current sys.stdout.
flush
whether to forcibly flush the stream.
4. Usando o módulo pydoc#
# Executar no terminal:
# python -m pydoc print
# python -m pydoc -p 8000
5. Consultando a documentação oficial#
6. Pesquisando em fóruns e comunidades#
"42" + "3
Cell In[6], line 1
"42" + "3
^
SyntaxError: unterminated string literal (detected at line 1)
Enfrentando erros#
Se você vir a mensagem de erro SyntaxError: EOL while scaning string literal , provavelmente esqueceu o caractere de aspas simples final no final da string, como neste exemplo
'Ola Mundo'
print('Ola Mundo)
É importante ter uma “mentalidade construtiva” em relação à programação – em outras palavras, entender que as pessoas desenvolvem habilidades de programação através da prática.
Inserindo Expressões#
2 + 3 * 6
2 ** 8
23 / 7
22 % 2
23 % 2
24 // 8
Instalando Módulos de Terceiros#
Alguns códigos Python exigem que seu programa importe módulos. Alguns desses módulos vêm com Python, mas outros são módulos de terceiros criados por desenvolvedores fora da equipe principal de desenvolvimento do Python.
import math
math.sqrt(4)
Precedência#
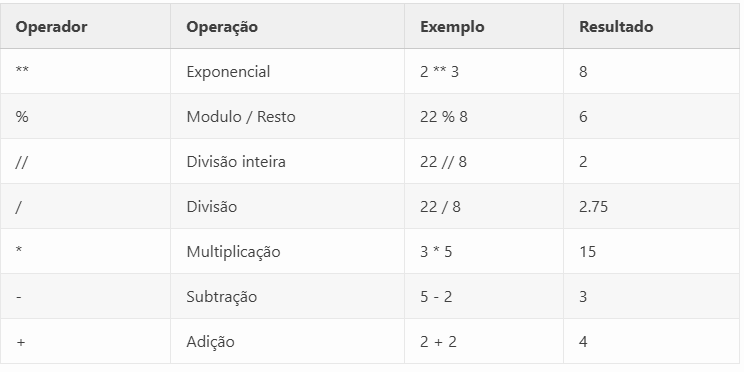
A ordem das operações (também chamada de precedência ) dos operadores matemáticos do Python é semelhante à da matemática.
O operador ** é avaliado primeiro; os operadores * , / , // e % são avaliados a seguir, da esquerda para a direita; e os operadores + e - são avaliados por último (também da esquerda para a direita).
Você pode usar parênteses para substituir a precedência usual, se necessário. O espaço em branco entre os operadores e os valores não importa para o Python (exceto o recuo no início da linha), mas um único espaço é uma convenção.
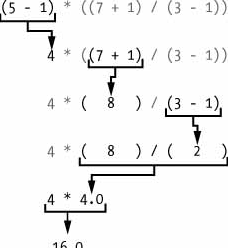
5 - 1 * ((7 + 1) / (3 - 1))
(5 - 1) * ((7 + 1) / (3 - 1))
Python continuará avaliando partes da expressão até que ela se torne um valor único, conforme mostrado aqui
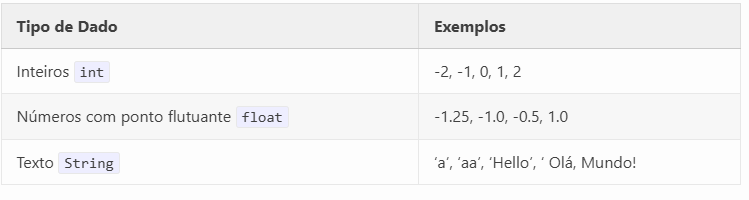
Tipos de dados inteiro, ponto flutuante e string#
Concatenação e replicação de strings#
'Alice' + 'Bob'
'Alice' + 42
'Alice' * 5
'AliceAliceAliceAliceAlice'
'Alice' * 5.0
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[2], line 1
----> 1 'Alice' * 5.0
TypeError: can't multiply sequence by non-int of type 'float'
Armazenando Valores em Variáveis#
Uma variável é como uma caixa na memória do computador onde você pode armazenar um único valor. Se quiser usar o resultado de uma expressão avaliada posteriormente em seu programa, você pode salvá-lo dentro de uma variável.

Declarações de Atribuição#
Você armazenará valores em variáveis com uma instrução de atribuição . Uma instrução de atribuição consiste em um nome de variável, um sinal de igual (chamado operador de atribuição ) e o valor a ser armazenado. Se você inserir a instrução de atribuição spam = 42 , então uma variável chamada spam terá o valor inteiro 42 armazenado nela.
spam = 42
spam
spam = 10
num1 = 2
spam + num1
Uma variável é inicializada (ou criada) na primeira vez que um valor é armazenado nela. Depois disso, você poderá utilizá-lo em expressões com outras variáveis e valores . Quando um novo valor é atribuído a uma variável , o valor antigo é esquecido. Isso é chamado de sobrescrever a variável.
spam + num1 + spam
spam = spam + 2
spam
spam = 'Hello'
spam

spam = 'Goodbye'
spam
spam = input()
spam
spam = spam + " à engenharia"
spam
spam = spam + 1
spam = input()
spam
spam = spam + 1
spam = int(spam)
spam
spam = spam + 1
spam
int(.70975858858) + 1
num2 = 20
num2 = num2 + 1
num2
Nomes de variáveis#
Um bom nome de variável descreve os dados que ela contém. Imagine que você se mudou para uma nova casa e rotulou todas as suas caixas de mudança como “Coisas” . Você nunca encontraria nada! Em seus programas, um nome descritivo ajudará a tornar seu código mais legível.
Embora você possa nomear suas variáveis de quase qualquer coisa, o Python tem algumas restrições de nomenclatura.
Você pode nomear uma variável como quiser, desde que ela obedeça às três regras a seguir:
Pode ser apenas uma palavra sem espaços.
Ele pode usar apenas letras, números e o caractere de sublinhado ( _ ).
Não pode começar com um número.
Os nomes das variáveis diferenciam maiúsculas de minúsculas, o que significa que spam , SPAM , Spam e sPaM são quatro variáveis diferentes. Embora Spam seja uma variável válida que você pode usar em um programa, é uma convenção do Python iniciar suas variáveis com uma letra minúscula.
Usamos o estilo camelcase para nomes de variáveis em vez de sublinhados; isto é, variáveis lookLikeThis em vez de looks_like_this

# This program says hello and asks for my name.
print('Hello, world!') # alô mundo
#print('What is your name?') # ask for their name
myName = input('What is your name?') #requer uma entrada do usuário e associa esta a variável myName
print(myName) #mostra na tela o conteúdo da variável
print('Hello, world ' + myName + '!') # alô mundo
A função print()#
A função print() exibe o valor da string entre parênteses na tela.
print('It is good to meet you, ' + myName)
Quando Python executa esta linha, você diz que Python está chamando a função print() e o valor da string está sendo passado para a função. Um valor passado para uma chamada de função é um argumento . Notar que as cotas (aspas) não são impressas na tela. Eles apenas marcam onde a string começa e termina; eles não fazem parte do valor da string.
print(f'It is good to meet you, ', myName)
A função len()#
Você pode passar para a função len() um valor de string (ou uma variável contendo uma string), e a função será avaliada como o valor inteiro do número de caracteres nessa string.
print('The length of your name is:')
print()
print(len(myName))
A função input()#
A função input() espera que o usuário digite algum texto no teclado e pressione ENTER
As funções str(), int() e float()#
Se você quiser concatenar um número inteiro com uma string para passar para print() , você precisará obter o valor ‘’ , que é a forma de string. A função str() pode receber um valor inteiro e será avaliada como uma versão de valor de string do inteiro, como segue:
print('What is your age?') # ask for their age
myAge = input()
print('You will be ' + str(int(myAge) + 1) + ' in a year.')
print('What is your age?') # ask for their age
myAge = input()
print('You will be ' + str(int(myAge) + 1) + ' in a year.')

As funções str() , int() e float() serão avaliadas nas formas string, inteiro e ponto flutuante do valor que você passa, respectivamente.
spam
'spam'
str(0)
str(-3.14)
int('42')
int('-99')
#int(1.25)
#int(1.99)
#float('3.14')
float(10)
A função str() é útil quando você tem um número inteiro ou flutuante que deseja concatenar com uma string. A função int() também é útil se você tiver um número como valor de string que deseja usar em alguma matemática. Por exemplo, a função input() sempre retorna uma string, mesmo que o usuário insira um número.
spam = input()
spam
spam * 10/5
O valor armazenado no spam não é o número inteiro, mas a string ‘’ . Se você quiser fazer contas usando o valor em spam , use a função int() para obter a forma inteira de spam e armazene-a como o novo valor em spam .
spam = int(spam)
spam
spam * 10/5
A função int() também é útil se você precisar arredondar um número de ponto flutuante para baixo.
int(7.7)
Equivalência ente números#
42 == '42'
42 == 42.0
42.0 == 0042.000
True
Exemplo na Engenharia Civil#
Um exemplo simples de aplicação na área de engenharia civil é o calculo da tensão normal em uma coluna. Para isso, nós iremos utilizar da seguinte formula:
Onde:
T = Tensão;
FN = Força Normal;
A = Área da seção transversal da coluna.
Exemplo - Calcule a tensão sobre a seguinte coluna:
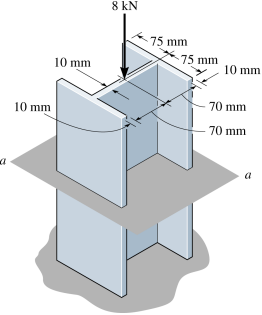
F = 8000
A = 10*(75+75)*2+(70+70)*10
T = F/A
print("A tensão foi de "+str(T)+" N/mm²")
A tensão foi de 1.8181818181818181 N/mm²
Referências#
https://automatetheboringstuff.com/
Al Sweigart. Automate the boring stuff with Python: practical programming for total beginners. No Starch Press, 2019.